Infrastructure as Code The Good the Bad and the Future

Bron: artikel integraal overgenomen van humanitec.com
Origineel auteur: Luca Galante

Infrastructure as Code is a key element of most top performing engineering setups. It’s a big leap forward in the way Ops and Devs interact with their own infrastructure. Interestingly, many still disagree on its definition and best practices. This article will clearly describe IaC, looking at both the its great benefits and crucial limitations.
Infrastructure as Code (IaC) is making waves in the world of software engineering, shaking up how Ops folks handle infrastructure setup and upkeep. But even though IaC has become pretty much the industry standard, there's still some serious debate going on about what exactly it is — and how to get it right. This article will take you on a journey through the history and future of infrastructure workflows. I’ll dive into what technologies were born out of the IaC evolution along with all the good stuff it offers, along with its limitations. Let's get started.
From Iron to Clouds
Remember the Iron age of IT, when you actually bought your own servers and machines? Me neither. Seems quite crazy right now that infrastructure growth was limited by the hardware purchasing cycle. And since it would take weeks for a new server to arrive, there was little pressure to rapidly install and configure an operating system on it. People would simply slot a disc into the server and follow a checklist. A few days later it was available for developers to use. Again, crazy.
With the simultaneous launch and widespread adoption of both AWS EC2 and Ruby on Rails 1.0 in 2006, many enterprise teams have found themselves dealing with scaling problems previously only experienced at massive multinational organizations. Cloud computing and the ability to effortlessly spin up new VM instances brought about a great deal of benefits for engineers and businesses, but it also meant they now had to babysit an ever-growing portfolio of servers.
The infrastructure footprint of the average engineering organization became much bigger, as a handful of large machines were replaced by many smaller instances. Suddenly, there were a lot more things Ops needed to provision and maintain and this infrastructure tended to be cyclic. We might scale up to handle a load during a peak day, and then scale down at night to save on cost, because it's not a fixed item. Unlike owning depreciating hardware, we're now paying resources by the hour. So it made sense to only use the infrastructure you needed to fully benefit from a cloud setup.
To leverage this flexibility, a new paradigm is required. Filing a thousand tickets every morning to spin up to our peak capacity and another thousand at night to spin back down, while manually managing all of this, clearly starts to become quite challenging. The question is then, how do we begin to operationalize this setup in a way that's reliable and robust, and not prone to human error?
Infrastructure as Code
IaC was born to answer these challenges in a codified way. Here's the deal. IaC is all about managing and setting up data centers and servers using machine-readable definition files. Ops teams can forget about complex hardware configs or having to rely on human-configured tools. With IaC, instead of having to run a hundred different config files, we simply hit a script that brings up a thousand machines every morning. Later the infrastructure is automatically brought back down to whatever the appropriate evening size should be. Talk about automation wizardry.
Now let's take a moment to rewind a little, back to a pivotal moment in the IaC timeline. In 2009 AWS CloudFormation launched and from this point, IaC quickly established itself as an essential practice in the DevOps world. It became an absolute must-have for a competitively paced software delivery lifecycle. And for good reason. IaC empowers engineering teams to rapidly whip up and version infrastructure, the same way they version source code. Engineers can also track versions to keep things consistent across environments. In short, it's like having a superpower for creating and managing infrastructure.
Typically, teams implement IaC as follows:
- Developers define and write the infrastructure specs in a domain-specific language
- Files are created and sent to a management API, master server, or code repository
- An IaC tool such as Pulumi then performs all necessary actions to create and configure the necessary computing resources
And voilá. Your infrastructure is suddenly working for you again instead of the other way around.
Traditionally there are two approaches to IaC: Declarative or imperative. There’s also two possible methods, push and pull. The declarative approach is all about describing the eventual target and it defines the desired state of your resources. This approach answers the question of what needs to be created, e.g. “I need two virtual machines”. The imperative approach is more about saying how infrastructure needs to be changed to reach a specific goal, usually by a sequence of different commands. Ansible playbooks for example are an excellent example of an imperative approach. The difference between the push and pull methods is simply around how the servers are told to be configured. In the pull method, the server pulls its configuration from the controlling server, while in the push method, the controlling server pushes the configuration to the destination system.
The IaC tooling landscape has been constantly evolving over the past ten years. So much so it would probably take a whole separate article to cover every approach you could take. Instead here’s a quick timeline of the main tools, sorted by GA release date:
- AWS CloudFormation (Feb 2011)
- Ansible (Feb 2012)
- Azure Resource Manager (Apr 2014)
- Terraform (Jun 2014)
- GCP Cloud Deployment Manager (Jul 2015)
- Serverless Framework (Oct 2015)
- AWS Amplify (Nov 2018)
- Pulumi (Sep 2019)
- AWS Copilot (Jul 2020)
IaC is an extremely dynamic vertical of the DevOps industry. Each year new tools and competitors are popping up while the old incumbents keep pushing the boundaries with new innovations. For example, just last year seasoned player CloudFormation rolled out their slick new feature Cloudformation modules in a bid to level up their game and keep things fresh.
The good, the bad
Thanks to a strong competitive push to improve, IaC tools have time and again innovated to create more end-user value. The biggest benefits for teams using IaC can be grouped into a few key areas:
-
Speed and cost reduction: IaC allows enables infrastructure config at speed. It helps teams work faster and smarter across the whole enterprise and frees up expensive resources to work on jobs that add real value. Scalability and standardization: IaC is the secret sauce for creating stable and scalable environments in a snap. It kills the need for any manual configuration of environments and enforces consistency by representing environments via code. Infrastructure deployments are repeatable and runtime issues caused by config drift or missing dependencies are minimized. Plus, IaC completely standardizes infrastructure setup, reducing errors and deviations.
-
Security and documentation: If all compute, storage and networking services are provisioned with code, they also get deployed the same way every time. This means security standards can be easily and consistently enforced across companies. Think of it like a bulletproof documentation system. IaC can also document infrastructure and insurance. With code that can be version controlled, IaC records, logs, and tracks every change to your server configuration. That’s safety and smarts all rolled into one, in the case of employees leaving your company with important knowledge.
-
Disaster recovery: As the term suggests, this one is pretty important. IaC is an extremely efficient way to track your infrastructure and redeploy the last healthy state after a disruption or disaster of any kind happens. Like everyone who woke up at 4am because their site was down will tell you, the importance of quickly recovering after your infrastructure got messed up cannot be understated.
There are definitely more specific advantages to particular setups. But generally speaking, this is where we see IaC having the biggest impact on engineering team workflows. And it’s far from trivial. Introducing IaC as an approach to manage your infrastructure could be your ticket to that crucial competitive edge. What many seem to miss though are its limitations. If you’ve already implemented IaC at your organization or have started, you’ll know it’s not all roses (like most IaC-related blog posts will have you believe). For an illustrative (and hilarious) example of the hardships of implementing something like Terraform, I highly recommend checking out The terrors and joys of terraform by Regis Wilson.
In general, introducing IaC also implies four key limitations you should know about:
-
Logic and conventions: It doesn’t matter if you’re using HashiCorp Configuration Language (HCL), Python, or Ruby. It's not so much about the language. The real challenge lies in getting your developers to understand the specific logic and conventions they need to apply — with confidence. Say only a small part of your engineering team is familiar with the declarative approach or other core IaC concepts. And Ops plus whoever else doesn’t get it. These guys will likely end up causing a bottleneck, something we’ve seen happen a lot in large enterprises dealing with legacy systems like .NET. If your setup requires everyone to understand these scripts to deploy their code, expect major roadblocks when it comes to onboarding and rapid scaling.
-
Maintainability and traceability: IaC is great for tracking infrastructure changes and monitoring things such as config drift. But here's the catch. As your organization grows (to approx 100+ developers in our experience), maintaining your IaC setup can become a challenge. When IaC is used extensively across the organization with multiple teams, things aren’t that straightforward when it comes to traceability and versioning of all those configs.
-
RBAC: Building on that, Access Management quickly becomes a pain too. Imagine having to set roles and permissions across different parts of your organization. And each one suddenly has access to scripts to easily spin up clusters and environments. Sweating yet?
-
Feature lag: Vendor agnostic IaC tooling (e.g. Terraform) often lags behind vendor feature release. This is because tool vendors need to update providers to fully cover the new cloud features being released at an ever-growing rate. The impact of this is sometimes you cannot leverage a new cloud feature unless you 1. extend functionality yourself 2. wait for the vendor to provide coverage or 3. introduce new dependencies.
When it comes to vendor-agnostic IaC tooling, like Terraform, there's something you should know. Sometimes, it might not keep up with the latest vendor feature releases. Here's why: tool vendors have to update their providers to fully support all the new cloud features that keep coming out at a rapid pace.
And guess what? This can create a bit of a challenge. There might be times when you can't take advantage of a shiny new cloud feature unless you do one of three things:
-
Take matters into your own hands and extend the tool's functionality yourself. It's like being a DIY expert and making it work just the way you want.
-
Wait for the tool vendor to catch up and provide coverage for that new feature. Patience is a virtue, right?
-
Introduce new dependencies to bridge the gap. Sometimes, it's like adding a little helper to connect the dots.
So, while vendor-agnostic IaC tooling has its perks, it's essential to be aware of this potential challenge. But hey, with some flexibility and a pinch of creativity, you can still make the most out of your cloud environment and stay ahead of the game! 🌟
Once again, these are not the only drawbacks of rolling out IaC across your company but are some of the more acute pain points we witness when talking to engineering teams. The future
As mentioned, the IaC market is in a state of constant evolution and new solutions to these challenges are being experimented with already. As an example, Open Policy Agents (OPAs) at present provide a good answer to the lack of a defined RBAC model in Terraform and are default in Pulumi.
The biggest question though remains the need for everyone in the engineering organization to understand IaC (language, concepts, etc.) to fully operationalize the approach. In the words of our CTO Chris Stephenson “If you don’t understand how it works, IaC is the biggest black box of them all”. This creates a mostly unsolved divide between Ops, who are trying to optimize their setup as much as possible, and developers, who are often afraid of touching IaC scripts for fear of messing something up. This leads to all sorts of frustrations and waiting times.
There are two main routes that engineering team currently take to address this gap:
-
Everyone executes IaC on a case by case basis. A developer needs a new DB and executes the correct Terraform. This approach works if everybody is familiar with IaC in detail. Otherwise you execute and pray that nothing goes wrong. Which works, sometimes.
-
Alternatively, the execution of the IaC setup is baked into a pipeline. As part of the CD flow, the infrastructure will be fired up by the respective pipeline. This approach has the upside that it conveniently happens in the background, without the need to manually intervene from deploy to deploy. The downside however is that these pipeline-based approaches are hard to maintain and govern. You can see the most ugly Jenkins beasts evolving over time. It’s also not particularly dynamic, as the resources are bound to the specifics of the pipeline. If you just need a plain DB, you’ll need a dedicated pipeline.
Neither of these approaches really solves for the gap between Ops and devs. Both are still shaky or inflexible. Looking ahead, Internal Developer Platforms (IDPs) built with a Platform Orchestrator can bridge this divide and provide an additional layer between developers and IaC scripts. By allowing Platform Engineers to set clear rules and golden paths for the rest of the engineering team, the Platform Orchestrator enables developers to conveniently self-serve infrastructure on every deployment, using a simple Workload Specification (e.g. Score). Developers just need to specify what resources their workloads need (DB, DNS, Storage) to deploy and run their applications while the Platform Orchestrator takes care of creating all the resources based on matching criteria set by platform engineers.
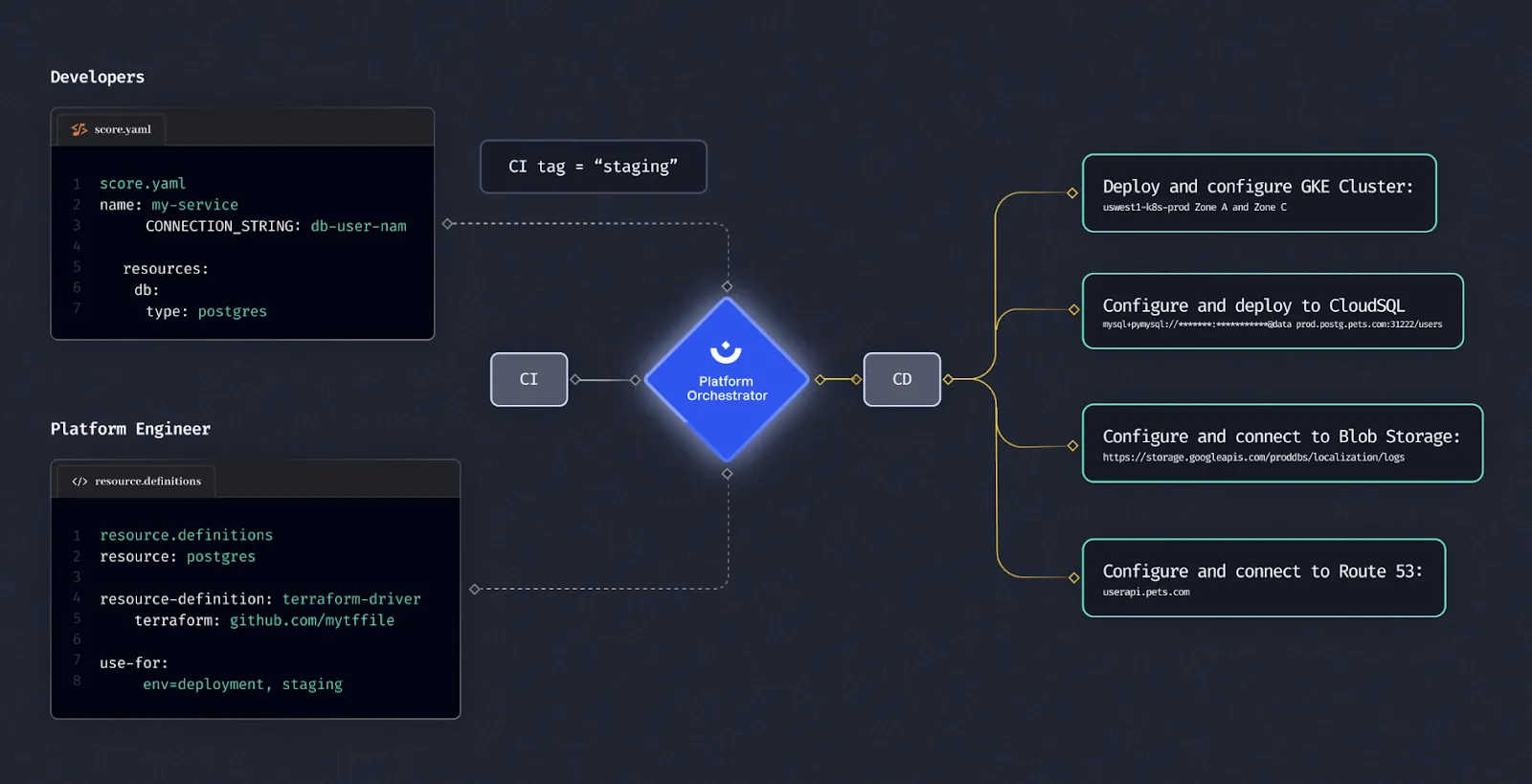
Platform Orchestrators are the logical next step in the evolution of Infrastructure as Code. Using it as the configuration engine at the heart of your platform layer, it lets you generate both app and infrastructure configurations (i.e. your IaC scripts) dynamically, with every new deployment. This not only makes your IaC (and overall delivery) setup much easier to maintain, it also cuts lead time and time to market by up to 40%. If you want to learn more about how a Workload Specification and Platform Orchestrator can work together to streamline your infrastructure and IaC setup, check out our product overview.